No.20 "규칙 기반 AI를 사용한 기계 학습 구현 : Corticon"
2017.09.01 Progress Corticon
이 항목은 Assist Co., Ltd. (https : //www.ashisuto.co.jp/product/category/brms/progress_corticon/column/detail/brmstech20.html)의 재 인쇄입니다.
|
|

이것은 2016 년 4 월부터 진행 제품을 담당 한 Tanahashi Hiroshi입니다. 최근에, 우리는 "AI", "딥 러닝"및 "딥 러닝"이라는 용어를 보게되었습니다. 반면에"기계 학습 ' 극적으로 감소했습니다. 이 단어의 차이점은 무엇입니까? 관심이 있다면 Michael Copeland는 "인공 지능, 기계 학습 및 딥 러닝의 차이점은 무엇입니까?" 2016 년 7 월 29 일 Nvidia의 공식 블로그에서.
우리에게 주제를 바꾸는 것은 우리 아이들을위한 길고 긴 여름 방학이 마침내 끝났습니다. 그 여름 방학 동안, 나는 아들의 수영과 켄도 토너먼트를 이끌었지만, 그 날에도 불구하고 나는 10 분도 채 걸리지 않았다. 그래서 나는 그 길고 자유 시간을 사용하여 딥 러닝에 관한 여러 책을 읽었습니다.
4 년 전, "기계 학습"제품을 Qlikview에 통합 한 커넥터를 개발했을 때, 우리가 처리하는 Qlikview에 "감독 학습"에 대해 배웠지 만 그 당시에 비해 변경된 점
1) 프로그래밍 언어는 이제 기계 학습 (딥 러닝)을 지원하고 자신의 방식으로 개발 및 사용에 사용할 수있게됩니다
2) 이제 CPU를 슬롯하지 않고 GPU로 처리
3) 다차원 및 적은 요소 분석 분석은 1 차원에서 멀티 요소 분석보다는 주류가되었습니다
그게 일어난 일이었습니다.
감독 학습
"기계 학습": "감독 학습"과 "감독되지 않은 학습"의 두 가지 방법이 있습니다. "딥 러닝"과 "딥 러닝"은 주로 "감독 학습"을 나타냅니다.
"감독 학습"은 교사 역할을하고 트렌드를 찾고, 새로운 이벤트에 적응하는 많은 모델 데이터를 분석하는 방법입니다. Google의 Alphago는 다양한 조정을 통해 CPU 처리 속도를 초과하고 인간을 물리 치는 GPU를 사용하여 전 세계 플레이어의 게임 레코드를 분석함으로써 유명해졌습니다. 이 "다양한 조정"은 승리 할 수있는 많은 시행 착오의 결과이며,이 부분은 확률 통계를 마스터하지 않으면 달성 할 수없는 것입니다. 또한 답이 올바르지 않으면 올바른 데이터를 반복해서 가져 와서 배워야합니다. 반면에 더 많은 모델 데이터를 사용하면 "오버러닝"이라는 부정적인 측면이 나타나서 전체 이벤트를 볼 수 없으므로 균형 조정이 필요합니다.
위에서 언급했듯이, "감독 학습"은 "다양한 조정"을 통해 답변에 더 가까이 갈 수 있도록하는 "모델 답변"의 한 유형이며,이 "다양한 조정"은 "감독 된 학습"의 핵심 부분이됩니다. 그리고 프로그래밍 언어가 머신 러닝 (딥 러닝)을 지원하기 시작했지만 일반화 된 매개 변수를 사용 하여이 "다양한 조정"에 불충분합니다. 그리고 기계 학습의 시행 착오 단계라고 생각합니다. 정확도가 불충분 할 때 무엇을 어떻게 해야하는지 결정할 수있는 방법을 찾을 수 없습니다. 이것은 Qlikview 커넥터를 개발 한 이후로 경험했던 것이었지만이 섹션이 더 쉬워 졌다는 책에 대한 언급은 없었습니다.
감독되지 않은 학습
'감독되지 않은 학습'은 '감독되지 않은 학습'과 같은 대답이 없음을 의미합니다. 그러나 답이 없더라도 목표 없이는 배울 수 없습니다. "감독되지 않은 학습"의 예로서 Google Deepmind의 "DQN"을 통해 컴퓨터는 게임 자체를 차단하는 규칙을 배울 수있어 인간보다 높은 점수를 얻을 수 있습니다.
"감독되지 않은 학습"의 경우에는 대답이 없지만 "높은 점수"라는 목표가 있습니다.
"감독되지 않은 학습"에 나타나는 제안은 "Multi-Arm Bandit"입니다. 이 제안을 고려해 봅시다.
"Win"과 "Missing"또는 "Missing"중에서 선택할 수있는 슬롯 머신 (Lottery Machine)이 있습니다.
이제 슬롯 머신 A가 70% 확률로 "승리"와 40%의 확률로 "승리"를 얻는 슬롯 머신 B가 있습니다.
가장 "승리"를 어떻게 선택합니까?
"감독 학습"의 경우
1) 슬롯 머신을 10,000 번 실행하면 "승리"의 기회는 약 70%가됩니다.
2) 슬롯 머신 B 10,000 배를 실행하면 "승리"의 기회는 약 40%입니다.
3) 슬롯 머신 A와 슬롯 머신 B의 결과를 비교하고 최대 값을 최대화하려면 슬롯 머신 A를 계속 실행하십시오.
결과는입니다.
그러나 "감독되지 않은 학습"에서 사용 가능한 정보 만 실행 결과입니다. 당신은 무엇을 하시겠습니까?
감독되지 않은 학습, 일반적인 기술
"확률이 높은 슬롯 머신의 복권"은 간단하고 간단합니다. 그러나 "확률이 우수한 슬롯 머신"의 정의는 불분명합니다. 실행 결과에 대한 명확한 정의 없이는 두 번 또는 10 번의 실행없이 프로그램을 작성할 수 없습니다.
예를 들어, "다음 번에 확률이 좋은 슬롯 머신을 사용하기 위해 누적 결과를 비교하십시오. 결과가 동일하면 다음에 다른 슬롯 머신이 사용됩니다. 규칙이 명확합니다.
1) 슬롯 머신 실행 A.
불행히도, 나는 "출력"의 30%를 잃게되었습니다.
슬롯 머신 A의 "승리"를 빼는 누적 결과는 0%이므로 다음에 슬롯 머신 B로 이동합니다.
슬롯된.
2) 슬롯 머신 실행 B
우연히, 나는 "퍼센트"의 40%를 빼기를 끝내었다.
슬롯 머신 A (0/1) 0% 및 슬롯 머신 B (1/1) 100%의 누적 결과와 비교하여 다음은 슬롯 머신 B
슬롯된.
3) 슬롯 머신 A의 확률은 0%이므로 슬롯 머신 B를 계속 사용하여 약 40%가됩니다.
그러나이 방법은 확률이 높은 슬롯 머신이 첫 번째 드로우에서 "누락 된"드로우를 그리면 잘못된 선택이라는 것을 의미합니다.
| 누적 시도 수 | 슬롯 머신 A (70%) | 슬롯 머신 B (40%) | ||||
| by Machine 시험 수 |
결과 | by machine 확률 |
by machine 시험 수 |
결과 | by machine 확률 |
|
| 1 | 1 | not | 0/1 = 0% | |||
| 2 | 1 | per | 1/1 = 100% | |||
| 3 | 2 | 슬롯할 수 없음 | 1/2 = 50% | |||
| 4 | 3 | 슬롯할 수 없음 | 1/3 = 33% | |||
| 5 | 4 | per | 2/4 = 50% | |||
| 6 | 5 | per | 3/5 = 60% | |||
| 7 | 6 | 아님 | 3/6 = 50% | |||
| 8 | 7 | 아님 | 3/7 = 42% | |||
| 9 | 8 | 좋지 않음 | 3/8 = 37% | |||
| 10 | 9 | not | 3/9 = 33% | |||
인간은 목표를 알고 있기 때문에 어떻게 든 올바른 방법으로 슬롯 머신을 선택할 계획입니다. 위에서 언급 한 "다양한 조정"입니다. 이것은 "감독되지 않은 학습"과 동일합니다. 어떤 의미에서, 이것은 불공평하다고 느끼는 부분입니다.
감독되지 않은 학습, 다양한 조정
위의 규칙에 다음 조건을 추가하겠습니다.
첫 번째 실행 슬롯 머신 B의 결과와 첫 번째 실행 슬롯 머신 A의 결과를 두 번 비교하십시오.
그 후에 확률이 좋은 슬롯 머신 사용
꽤 좋은 '조정'입니다. 이것은 가설 테스트에 대한 AB 테스트입니다. 이 "실행 (테스트) 슬롯 머신 A 두 번"을 "탐색"이라고합니다. 검색 결과를 기반으로 특정 슬롯 머신의 사용을 "탐색"및 "Exploit"이라고합니다.
이 열은 확률/통계가 아니므로 계산하고 싶습니다 : 슬롯 머신 B는 약 15%로 선택됩니다.
'탐색'이 두 번 충분합니까? 10 배 충분합니까? 기본적으로, 확률 만으로이 제안을 이해하기가 어렵습니다. 당신은 몇 가지 다른 접근법이 필요합니다.
감독되지 않은 학습 UCB1 알고리즘
다음 전형적인 알고리즘을 포함 하여이 제안을 수행하기위한 다양한 알고리즘이 만들어졌습니다.
■ Epsilon-Greedy 알고리즘
■ SoftMax 알고리즘
■ UCB1 (상한 신뢰 1 바이드 알고리즘) 알고리즘
이 기사는 알고리즘을 설명하지 않으므로 독자에게 각 알고리즘의 세부 사항을 조사하고 UCB1 알고리즘의 공식을 평가하도록 요청합니다.
|
|
"이 슬롯 머신에서 누적 히트 곡이 생성되었습니다
n "이 슬롯 머신에 그려진 누적 시도 수
n 모든 슬롯 머신에 그려진 누적 시도
C 상수
이 UCB 알고리즘을 사용하여 "탐색"을하고 책상에서 다음 규칙을 연습 해 보겠습니다.
모든 슬롯 머신을 초기 값으로 실행하고 UCB1 값을 출력
UCB1 값이 가장 높은 슬롯 머신 선택
UCB1 값이 가장 큰 슬롯 머신이 여러 개있는 경우 마지막 슬롯 머신을 선택하십시오
상수 C를 2
| 누적 시도 수 | 슬롯 머신 A (70%) | 슬롯 머신 B (40%) | ||||||
| by machine 시험 수 |
결과 | by machine 확률 |
by machine UCB1 값 |
by machine 시험 수 |
결과 | by machine 확률 |
by machine UCB1 값 |
|
| 1 (최초 값 획득) | 1 | 좋지 않음 | 0/1 = 0% | 0 | - | |||
| 2 (최초 값 획득) | 1.665 | 1 | per | 1/1 = 100% | 2.665 | |||
| 3 | 2.096 | 2 | not | 1/2 = 50% | 1.982 | |||
| 4 | 2 | not | 0/2 = 0% | 1.665 | 1/3 = 33% | 2.165 | ||
| 5 | 1.794 | 3 | 좋지 않음 | 1/3 = 34% | 1.798 | |||
| 6 | 1.893 | 4 | not | 1/4 = 25% | 1.589 | |||
| 7 | 3 | per | 1/3 = 34% | 1.944 | 1.645 | |||
| 8 | 4 | per | 2/4 = 50% | 1.942 | 1.692 | |||
| 9 | 5 | per | 3/5 = 60% | 1.926 | 1.732 | |||
| 10 | 6 | per | 4/6 = 67% | 1.906 | 1.767 | |||
슬롯 머신을 더 자주 선택 해야하는 것 같습니다. 우연의 일치이든 피할 수 없는지 여부를 확인하려면 시험 수를 늘려야합니다.
Corticon을 슬롯하여 UCB 알고리즘 구현
Corticon의 이전 섹션에서 슬롯 된 규칙을 구현합시다.
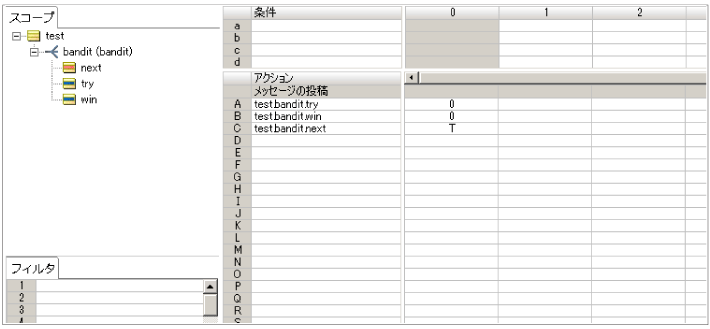
먼저 슬롯 머신을 만듭니다. 이것은 임의의 숫자 생성기 인 다음 연산자를 사용합니다.
randomgenerator.getrandomnumber
이 연산자는 0보다 큰 '소수점'유형의 값을 만듭니다.이 값의 4 번째 소수점 수를 꺼내서 0에서 9까지의 단일 문자를 만들었습니다.
(((randomgenerator.getrandomNumber * 10000) .tointeger) .mod (10)). Tostring
내 경험상 임의의 숫자 생성 기능은 매우 바이어스 된 값을 갖는 경향이 있으므로 소수점 이하 자리의 숫자를 사용합니다. 또한 규칙 테스트에서 위의 스크립트를 여러 번 테스트했으며 생성 된 숫자의 발생률이 거의 1/10임을 확인했습니다.
나머지는 축적 된 복권 결과를 유지하는 규칙 시트에 추가됩니다. 슬롯 머신 A와 B가 실행되는 횟수를 표시하고 "Per"의 횟수는 표시됩니다.
Bandit.ecore
|
|

볼륨 속성 및 설정
| 엔티티 이름 | 속성 이름 | 데이터 유형 | 필수 | 모드 | 설명 |
| Bandit | 슬롯 머신이 될 것입니다 | ||||
| 최신 | 정수 | 아니오 | 과도 | 런타임 시도 카운터 | |
| 다음 | 부울 | 아니오 | 과도 | 사용할 다음 슬롯 머신은 사실입니다 다음에 사용되지 않을 슬롯 머신은 False를 유지합니다 |
|
| 번호 | String | 예 | 베이스 | "per"로 결정될 숫자 문자열 | |
| 결과 | 부울 | 아니오 | 베이스 | "per"인 경우 참 보존; 거짓이지 않은 경우 | |
| try | 정수 | 아니오 | Base | 기계 당 누적 시도 수 | |
| UCB1 | Decimal | 아니오 | 과도 | UCB1 값 계산 및 유지 | |
| WIN | Integer | 아니오 | Base | 기계에 의한 "per"에 대한 누적 횟수 | |
| WSTRING | String | 아니오 | 과도 | 1 문자 번호 랜덤 숫자 생성기를 사용하여 그려 됨 | |
| 테스트 | 검증 환경이 될 것입니다 | ||||
| expectionNumberOftrials | 정수 | 예 | Base | 예정된 시도 | |
| Numbertrials | 정수 | 아니오 | 과도 | 시험 카운트 카운터 | |
| UCB1_C | 십진 | 예 | 베이스 | UCB1 값을 계산할 때 사용되는 상수 C의 값 | |
| Bandit (Bandit) | 산적과의 1 : N 관계 만들기 | ||||
Corticon에서 일반적인 규칙을 만들려면 다음에 Nextn이라는 속성을 만들었습니다. 이들은 프로그래밍 언어로 만들 때 필요하지 않은 변수입니다.
먼저, 속성을 초기화하기 위해 두 개의 슬롯을 작성하십시오. 또한이 두 개의 초기화 슬롯 시트가 실행되는 순서는 중요하지 않습니다.
초기화 1.ers
|
|
Zero는 테스트 엔티티의 숫자 - 명성 속성을 지 웁니다.
초기화 2.ERS
|
|
Zero는 Bandit Entity의 시도 및 승리 속성을 지 웁니다. 또한 t (true)로 다음 속성을 지우십시오.
마지막 으로이 처리 부분에 대한 규칙을 만들 시간입니다. 먼저 특정 슬롯 머신을 그리는 규칙을 작성하십시오.
banditforloop.ers
|
|
확대하려면 이미지를 클릭하십시오
임의의 숫자는 Bandits.WString에 랜덤 숫자를 사용하여 LINE 0에 생성됩니다.
또한 Machine, Test.bandit.try의 누적 시도 수가 계산됩니다. 카운터, test.numberoftrials의 시도 수도 계산됩니다. 다음으로, String Bandits.wString 조건부 항목 열에서 생성 된 STRING이 Preset String Test.bandits.number에 존재하는지 확인하십시오. 그렇다면 "per"이고 t (true)를 test.bandits.result로 설정합니다. 또한 "per"(주변)의 경우 기계 별 "Perround"에 대한 축적 된 드로우 수가 계산됩니다.
이 방법으로 슬롯 머신의 확률은 test.bandits.number로 설정된 문자에 의해 결정됩니다. 7자가 설정되면 70% 확률이 있으며 4자가 설정되면 40%의 기회가 있습니다.
UCB1 값을 계산할 규칙을 만듭니다.
ucb1.ers
|
|
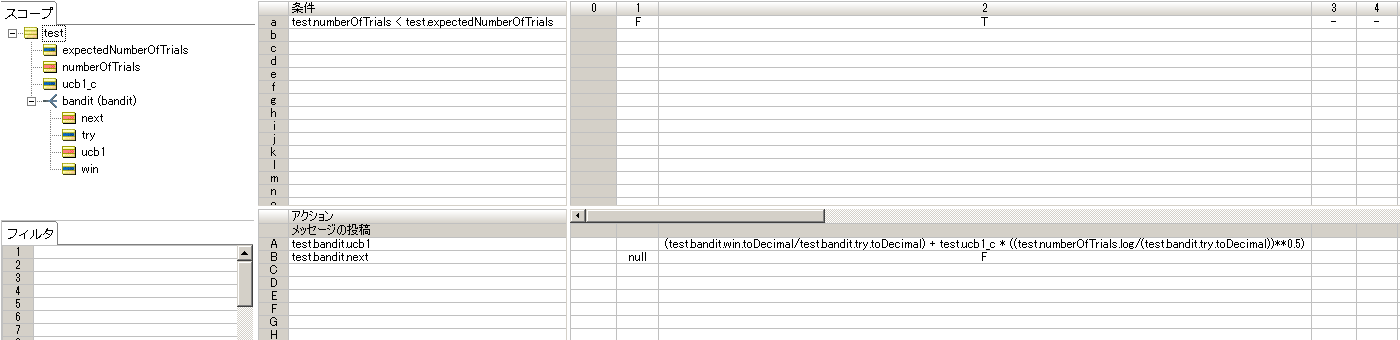
확대하려면 이미지를 클릭하십시오
그리기하려는 슬롯 머신은 필터를 사용하여 산적을 설정합니다 .next = t. 모든 슬롯 머신은 항상 초기 처리 중에 실행되므로 초기화는 모든 슬롯 머신의 경우 t로 t로 설정합니다.
초기 처리 후 T는 항상 산적으로 하나의 장치로 설정되며 예정된 시도 횟수가 초과되면 NULL이 설정됩니다.
예정된 시도의 수가 예정된 시도 수보다 작거나 동일하다면, 모든 슬롯 머신의 UCB1 값을 계산하고 Test.Bandit.ucb1 속성에 저장하고 다음에 실행할 슬롯 머신을 결정합니다. 예정된 시도 횟수가 초과되는 경우 NULL 설정
다음에 실행할 슬롯 머신을 결정하는 2 단계 규칙을 작성하십시오.
next1.ers
|
|
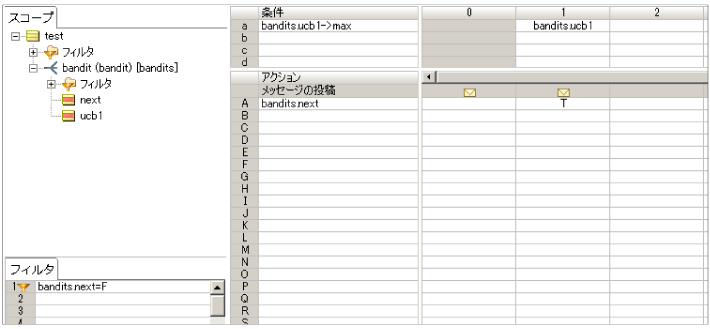
가장 큰 UCB1 값의 슬롯 머신을 선택하려면 컬렉션 연산자를 사용하여 산적을 설정합니다.
UCB1 값이 동일하면 이전 슬롯 머신이 사용된다는 규칙을 구현하십시오.
next2.ers
|
|
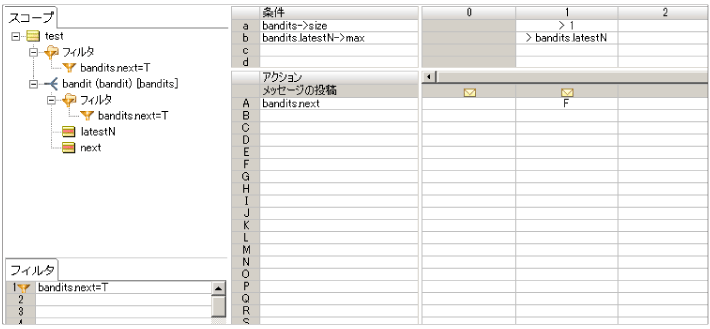
매번 드로우 할 때마다, test.numberoftrials가 중고 슬롯 머신의 latestn 속성으로 설정되므로 (마지막 슬롯 머신) = (큰 산적이있는 슬롯 머신).
RuleFlow와 함께 위의 슬롯을 제어하십시오.
test.erf
|
|
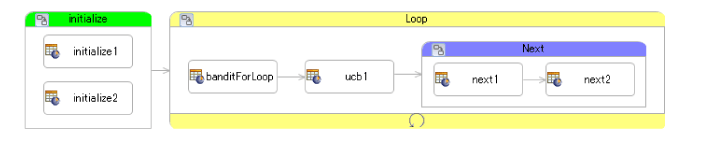
루프라는 서브 플로를 만듭니다. 마지막 으로이 루프 하위 흐름에 대한 루프를 설정했습니다.
* brms.propaties의 루프 설정
이것이 규칙 설정을위한 전부입니다. 우리는 마침내 시험을 실시 할 예정이지만 시험 수는 50,000이 될 것으로 예상합니다. Corticon의 기본 설정은 최대 루프 수를 100으로 제한 하므로이 값을 증가시켜야합니다.
com.corticon.reactor.rulebuilder.maxloops = 100000
위 설정은 상한을 1,000,000 배로 설정하는 것입니다. 속성 파일을 덮어 씁니다. 자세한 내용은 Corticon Studio : Quick Reference Guide, Page 13 또는 Corticon Server : Integration and Deployment Guide, 부록 C : Corticon 속성 및 설정 구성, "Oredide File BRMS.Properties 사용"을 참조하십시오.
이제 테스트를 설정하십시오.
Text.expectedNumberOftrials에 대해 50000을 설정합니다. 두 개의 슬롯 머신을 설정하십시오. 두 개의 테스트를 만듭니다. 복권 확률은 두 개의 슬롯 머신으로 설정됩니다. 하나의 기계는 70%이므로 7자를 test.bandit (bandit)에서 설정하여 "1246890"으로 설정했습니다. 복권에서 이길 가능성은 70%입니다. 하나의 기계가 40%이므로 문자열 "2468"을 test.bandit (bandit) .number로 설정했습니다. 복권에서 이길 가능성은 40%입니다.
지금 해보자.
test.ert
|
|
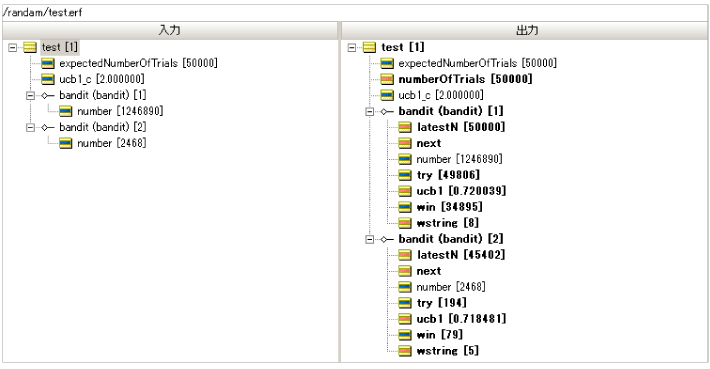
| 항목 | 슬롯 머신 A Bandit (Bandit) [1] |
슬롯 머신 B Bandit (Bandit) [2] |
| 기계 당 누적 시도 수 | 49806 | 194 |
| "Per"에 대한 누적 횟수 | 34895 | 79 |
| 기계에 의한 "per"확률 | 34895 / 49806 = 0.701 | 79/194 = 0.407 |
| 기계 선택 비율 | 49806 / 50000 = 0.996 | 194 / 50000 = 0.004 |
슬롯 머신 A의 확률은 70%이고 슬롯 머신 B의 확률은 40%입니다.
놀라운 비율은 이제 슬롯 머신 A를 거의 97%로 선택했습니다.
믿을 수없는 숫자가 공개되었으므로 100,000 번 확인해 봅시다.
test.ert
|
|
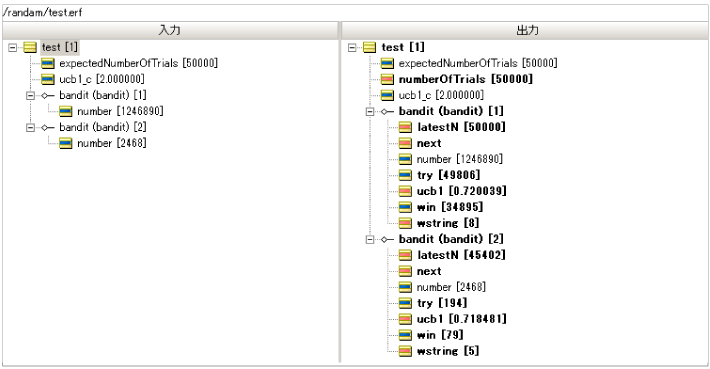
| item | 슬롯 머신 A Bandit (Bandit) [1] |
슬롯 머신 B Bandit (Bandit) [2] |
| 기계 당 누적 시도 수 | 99785 | 215 |
| 기계에 의한 "per"에 대한 누적 횟수 | 69882 | 88 |
| 기계에 의한 "per"확률 | 69882 / 99785 = 0.700 | 88/215 = 0.409 |
| 기계 선택 비율 | 99785 / 100000 = 0.998 | 215 / 10000 = 0.002 |
따라서 시간 수를 크게 줄이고 100 배로 테스트 해 봅시다.
test.ert
|
|
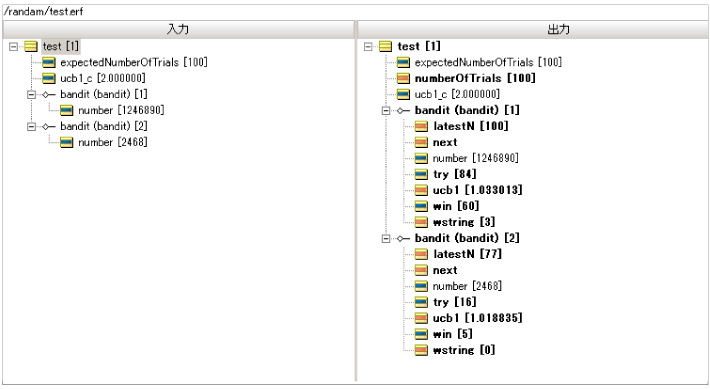
| 항목 | 슬롯 머신 A Bandit (Bandit) [1] |
슬롯 머신 B Bandit (Bandit) [2] |
| 기계 당 누적 시도 수 | 84 | 16 |
| 기계에 의한 "per"에 대한 누적 횟수 | 60 | 5 |
| 기계에 의한 "per"확률 | 60/84 = 0.714 | 5/16 = 0.313 |
| 기계 선택 비율 | 84 / 100 = 0.84 | 16 / 100 = 0.16 |
이제 20% 확률로 슬롯 머신 C를 증가시키고 슬롯 머신 D를 10% 확률로 늘리고 50,000 회로 다시 시도해 봅시다.
test.ert
|
|
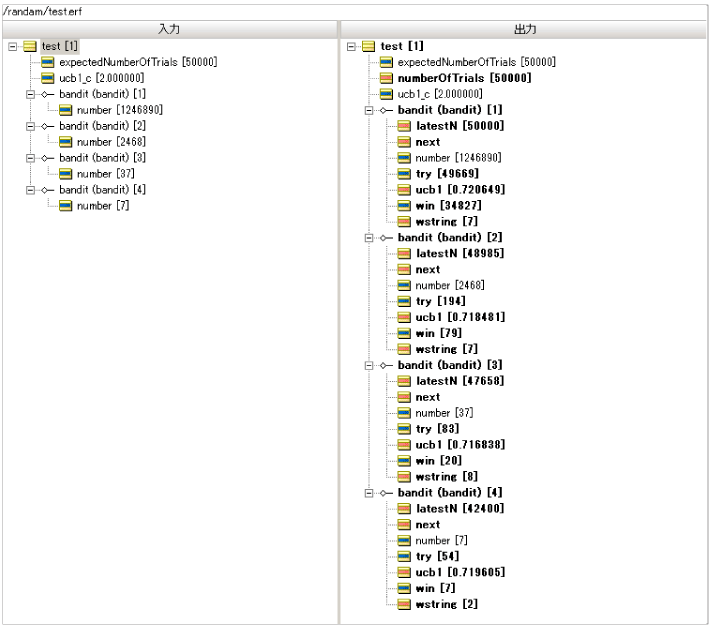
| 항목 | 슬롯 머신 A Bandit (Bandit) [1] |
슬롯 머신 B Bandit (Bandit) [2] |
슬롯 머신 C Bandit (Bandit) [3] |
슬롯 머신 D Bandit (Bandit) [4] |
| 기계 당 누적 시도 수 | 49669 | 193 | 84 | 54 |
| 기계에 의한 "per"에 대한 누적 횟수 | 34827 | 79 | 20 | 7 |
| 기계에 의한 "per"확률 | 34827 / 49669 = 0.701 | 79 / 194 = 0.407 | 20/83 = 0.241 | 7 / 54 = 0.123 |
| 기계 선택 비율 | 49669 / 50000 = 0.9936 | 194 / 50000 = 0.004 | 83 / 50000 = 0.001 | 54 / 50000 = 0.001 |
마침내
감독되지 않은 학습 알고리즘이 개선 될 수 있거나 다른 알고리즘이 향후 나타날 수 있지만 UCB1 (상한 신뢰 바인드 1 알고리즘) 알고리즘은 매우 우수하며 비즈니스 분야에서 다양한 방식으로 적용 할 수있는 것 같습니다.
반면에, 비즈니스에서 슬롯할 때는 일정한 C의 값을 결정하는 방법과 계산 된 값을 슬롯하는 방법에 시행 착오가 필요합니다.
우리는 종종 "코르티콘을 사용하여 기계 학습을 배울 수 있습니까?"와 같은 질문을받습니다. 대답은 위에서 언급했듯이 "할 수있다"는 것이지만 Corticon은 시행 착오 부분을 수행 할 수 없습니다. 즉, 상수 C를 결정하거나 계산 된 확률을 사용하는 방법을 결정하는 것은 결정이 아닙니다.
코르티콘이 많은 알고리즘과 여러 상수 패턴으로 템플릿을 구현하더라도 인간은 결국 어떤 알고리즘과 어떤 상수 C를 슬롯하는지에 대한 결정을 내려야하며,이 부분은 불행히도이 부분을 자동화 할 수 없습니다.
또한 기계 학습을 사용하여 결과가 도출 된 이유를 분석하는 것은 거의 불가능하다고 말합니다. 반대로, 알고리즘 A 또는 알고리즘 B를 사용할지 또는 2.0 또는 1.0의 상수 C를 사용할 것인지는 쉽게 알 수 없습니다.
슬롯 러닝은 여전히 여기에서 먼 길이 인 것 같습니다.
